2021. 12. 29. 01:31ㆍcomputervision/섹션 3. RCNN 계열 Object Detecter(RCNN, SPPN
R-CNN(Regions with CNN)
RCNN의 전체적인 구조를 보면 아래 그림과 같다

먼저 Selective search부분에서 2000개의 proposal된 region을 추출하게 된다.
그 후 ImageNet 데이터 set으로 pretrained된 학습 모델에 2000개의 region을 fine-tuning 하게 된다.
여기서 RCNN모델의 Classification Dense Layer로 인해 이미지의 크기가 모두 동일해야 하므로 추출된 2000개의 이미지 사이즈를 동일하게 ratio를 맞추주는 과정을 거치게 된다.
RCNN Training에서 Classification부분을 좀 더 자세히 살펴보면 아래 그림과 같은 구조로 이루어져 있다.

원본 이미지에서 Selective Search을 시키고 이후 학습 과정에서 Ground Truth와 Selective Search가 예측한 영역의 IOU가 0.5 이상인 경우만 해당 Ground Truth의 클래스로 학습이 적용되고, 나머지의 경우는 모두 Background로 fine-tuning을 진행하게 된다.
이후 1-D형태로 Flattened fully connected layer를 얻어 이후 한번의 학습을 더 진행해주게 된다.
일반 적인 CNN모델의 경우 최종 얻은 layer에서 softmax를 진행하여 classification을 진행한다. 하지만 RCNN모델에서는 SVM을 이용하여 이후의 학습을 한번 더 거치게 된다.
이때 Ground Truth로만 학습을 하되 0.3 IOU 이하는 Background로 설정하고 IOU 0.3이상이지만 Ground Truth가 아닌 경우는 최종적으로 분류해야될 object가 아니기 때문에 학습에서 제외한다.
Bounding Box Regression 부분
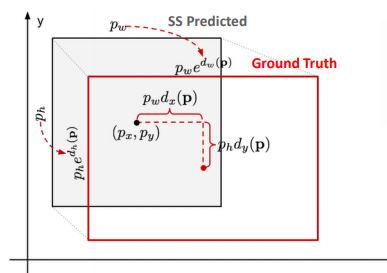
위와 같은 구조로 Regression을 진행해주게 된다.
Regression이므로 당연히 loss값을 정하여야된다.
가장 최적의 loss를 구하기 위해서는 SS Predicted의 중앙좌표 값과 Ground Truth의 중앙좌표 값의 차이가 적어야 되고, 두개의 bounding box의 width와 height의 차이가 적어야 될 것이다.

예측 값은 위와 같으며 딥러닝 모델은 d(P)부분을 학습해야 될 것이다.

target 값은 위와 같은 식으로 나타낼 수 있을 것이다.
그렇다면 loss function은
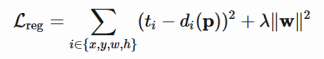
위와 같은 식으로 (target - predict) 정리될 수 있을 것이다.
RCNN의 성능 비교

위의 표에서 보다 싶이 RCNN은 다른 기법에 비해 보다 획기적인 성능을 보여주었다.
RCNN의 장단점
먼저 장점으로는 높은 Detection 정확도를 보여준다는 점이다.
하지만 너무 느린 Detection 시간과 복잡한 구조 및 학습 프로세스를 가지고 있다는 단점이 존재한다.
대락 1장의 이미지를 object dectection하는데 약 50초 가량이 소요된다고 한다.
하지만 RCNN이후 딥러닝 기반 Object detection의 성능이 입증되었고
detection 수행 시간을 줄이고 복잡하게 분리된 개별 구조를 통합할 수 있는 연구가 진행됬다는 점에서 의미가 있다.
'computervision > 섹션 3. RCNN 계열 Object Detecter(RCNN, SPPN' 카테고리의 다른 글
| OpenCV dnn을 활용하여 실습하기 (0) | 2022.01.02 |
|---|---|
| Faster RCNN 개요 (0) | 2021.12.31 |
| Fast RCNN 개념 (0) | 2021.12.30 |
| SPP(Spatial Pyramid Pooling) Net 개요 (0) | 2021.12.30 |