2021. 12. 31. 16:35ㆍcomputervision/섹션 3. RCNN 계열 Object Detecter(RCNN, SPPN
Faster RCNN이란 간략하게 RPN와 Fast RCNN합친 방법으로 분류될 수 있다.
Faster RCNN의 구조
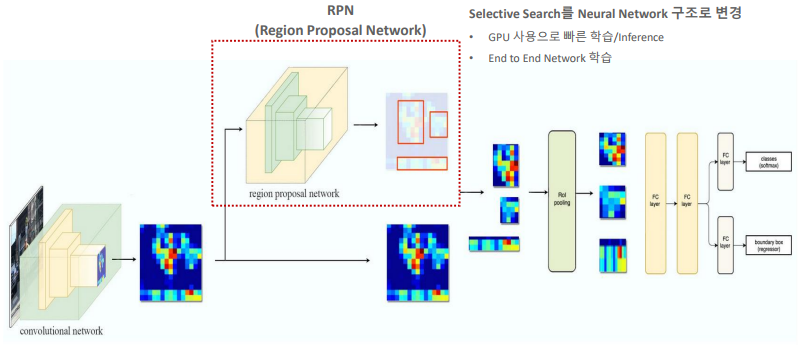
가장 Fast RCNN과의 큰 차이점은 중간에 RPN(Region Proposal Network) layer를 뒀다는 점에서 차이가 있다.
기존의 Selective Search방법을 NN구조로 변경했다.
또한 학습 방법에서도 차이점이 존재한다.(이후 설명)
RPN의 구현을 위해서는 필연적으로 Anchor Box의 도입이 필요했다.

Anchor Box는 하나의 Point에 총 9개의 서로다른 크기의 box로 구성된다.
여기서 Anchor Box는 원본 이미지 자체에 구현되는 것이 아니라 feature map에서 매핑된다는 점이 중요하다.
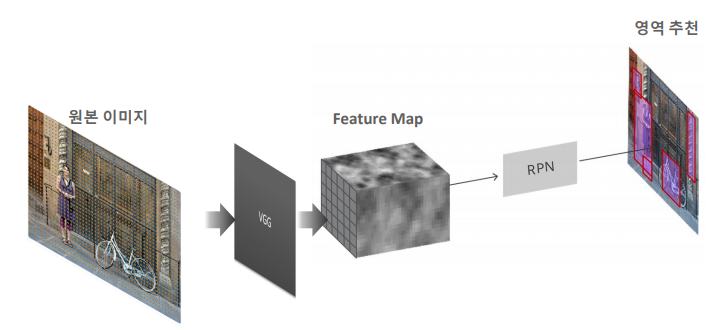
즉 원본 이미지가 들어오면 사전 학습된 VGG Net에서 학습을 거쳐 Feature Map 형태로 추출된다. 이때 feature map단계에서 RPN을 거쳐 object의 위치 detect하게 된다.
RPN 네트워크 구성
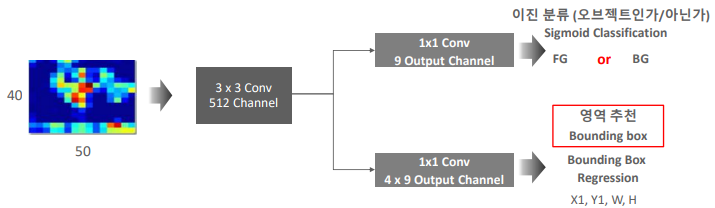
RPN네트워크는 위와 같이 도식적으로 나타낼 수 있다. (3*3 conv 512채널)의 네트웍이 들어오면 2개의 네트웍 구성으로나뉘어 지게 된다. 크게 classification과 regression의 두가지로 나뉘게 되는데 (1*1 conv 9 ouput channel)에서는 Sigmoid Classification으로 FG(foreground)와 BG(Background)로 분류하는 역할을 수행한다. FG와 BG로 나뉘는 기준은 Ground Truth BB가 겹치는 IOU에 따라 Positive Anchor Box, Negative Anchor Box로 분류된다. 이때 IOU가 0.7이상이면 Positive 0.3보다 낮으면 Negative로 나뉜다. (1*1 conv 4*9 output channel)에서는 bounding box영역 추천을 하는 네트워크가 이루어 진다. 이때 두 네트워크에서 9 output channel 이 되는 이유는 하나의 POINT 마다 9개의 Anchar box가 존재하기 때문이다.
실제 코드도 다음과 같이 구현되어 있다.

RPN Loss 함수

classification과 regression의 loss함수가 동시에 계산된다.
위의 loss함수에서는 당연히 Negative Ground truth Object가 Positive Ground truth Object보다 많을 수 밖에 없다.
따라서 이 둘간의 균형을 맞춰주기 위해 실제 학습에서는 Mini Batch 방법을 이용하여 둘간의 균형을 맞추어 준다.

Faster RCNN Training
faster rcnn에서 rpn과 fast rcnn을 합쳐서 학습하는 방법은 Alternating Training 방법이 쓰였다.

위의 그림에서 보라색으로 표시된 네트워크는 업데이트가 진행되지 않은 네트워크이다.
step 1에서는 RPN 네트워크와 VGG네트워크가 학습을 진행한다. 이후 step 2에서 step1에서 학습된 RPN을 이용해 추출된 영역(ROI)을 추출하여 이것을 이용해 fast rcnn을 학습한다. 이때 vgg도 같이 학습을 진행하게 된다. step 3에서는 step1과 step2에서 학습된 vgg를 통해 추출된 feature map을 이용해 RPN을 학습시키게 된다. step 4에서는 step1과 step2를 통해 학습된 vgg와 step 3을 통해 학습된 RPN을 이용해 최종 fast rcnn부분을 학습하게 된다.
Faster RCNN 성능과 수행시간 비교
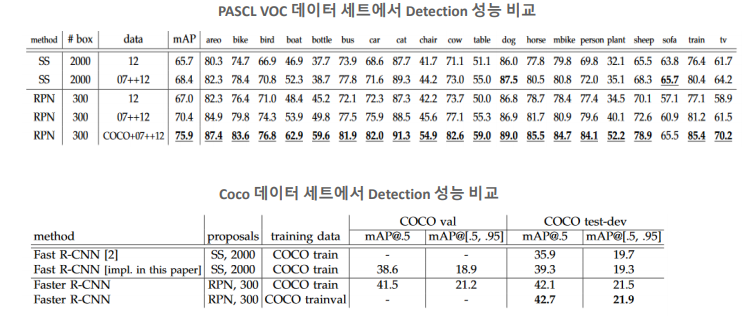
RPN layer를 이용해 학습시킨 모델에서 이전의 Selective Search방법을 이용했을 때 보다 성능이 소폭 향상된 것을 보였다. 하지만 detection의 성능보다 수행시간의 차이에서 큰 차이를 더 많이 보였다.

기존의 0.5 fps처리 능력을 보여주던 SS를 적용했을 때의 성능에서 같은 VGG NET을 사용했을때 대략 10배정도 빠른 성능의 차이를 보여주었다.
'computervision > 섹션 3. RCNN 계열 Object Detecter(RCNN, SPPN' 카테고리의 다른 글
| OpenCV dnn을 활용하여 실습하기 (0) | 2022.01.02 |
|---|---|
| Fast RCNN 개념 (0) | 2021.12.30 |
| SPP(Spatial Pyramid Pooling) Net 개요 (0) | 2021.12.30 |
| RCNN 개념 (0) | 2021.12.29 |