2022. 1. 2. 00:52ㆍcomputervision/섹션 3. RCNN 계열 Object Detecter(RCNN, SPPN

OpenCV DNN은 장단점이 존재한다.
장점으로는 딥러닝 개발 프레임 워크 없이 쉽게 inference가 구현 가능하다. 하지만 GPU 지원 기능이 약하며, 모델을 학습할 수 있는 방법을 제공하지 않으며 오직 inference만 가능하다는 단점이 뚜렸하게 존재한다.
OpenCV는 자체적으로 딥러닝 가중치 모델을 생성하지 않고 타 프레임워크(대표적으로 Tensorflow, Darknet, torch, caffe)에서 생성된 기존 모델을 변환하여 로딩하는 작업을 거친다.
https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API 에 접속해보면 다양한 Tensorflow 모델 리스트들이 나온다. 각 모델들의 Weights와 config파일이 존재하며 원하는 모델을 다운로드 받아 직접 적용해 볼 수 있다.
[실습]

먼저 위와 같은 이미지에서 object detection을 하는 작업을 수행한다.
Tensorflow에서 미리 학습된 Inference 모델과 환경파일을 다운받은 후 이를 활용해서 OpenCV에서 inference모델을 생성한다.

모델은 Faster-RCNN RestNet-50을 사용했다.
weights파일과 config파일을 다운받은 후 dnn에서 readNetFromTensorflow()로 선택한 모델을 로딩한다.
cv_net = cv2.dnn.readNetFromTensorflow('./pretrained/faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb',
'./pretrained/config_graph.pbtxt')다음으로는 이미 학습된 모델이 coco dataset 기반으로 학습되있으므로 coco 데이터 set의 클래스 id별 클래스명을 지정해야 한다. 여기서 약간의 issue가 있는데 coco 데이터 세트의 클레스id 별 클래스명이 사용자가 사용할 모델마다 라벨링이 다르게 되있다는 문제가 있다. 따라서 사용할 모델에 적절하게 매칭이 되있는 클래스명으로 사용하는 것이 중요하다.
# OpenCV Tensorflow Faster-RCNN용
labels_to_names_0 = {0:'person',1:'bicycle',2:'car',3:'motorcycle',4:'airplane',5:'bus',6:'train',7:'truck',8:'boat',9:'traffic light',
10:'fire hydrant',11:'street sign',12:'stop sign',13:'parking meter',14:'bench',15:'bird',16:'cat',17:'dog',18:'horse',19:'sheep',
20:'cow',21:'elephant',22:'bear',23:'zebra',24:'giraffe',25:'hat',26:'backpack',27:'umbrella',28:'shoe',29:'eye glasses',
30:'handbag',31:'tie',32:'suitcase',33:'frisbee',34:'skis',35:'snowboard',36:'sports ball',37:'kite',38:'baseball bat',39:'baseball glove',
40:'skateboard',41:'surfboard',42:'tennis racket',43:'bottle',44:'plate',45:'wine glass',46:'cup',47:'fork',48:'knife',49:'spoon',
50:'bowl',51:'banana',52:'apple',53:'sandwich',54:'orange',55:'broccoli',56:'carrot',57:'hot dog',58:'pizza',59:'donut',
60:'cake',61:'chair',62:'couch',63:'potted plant',64:'bed',65:'mirror',66:'dining table',67:'window',68:'desk',69:'toilet',
70:'door',71:'tv',72:'laptop',73:'mouse',74:'remote',75:'keyboard',76:'cell phone',77:'microwave',78:'oven',79:'toaster',
80:'sink',81:'refrigerator',82:'blender',83:'book',84:'clock',85:'vase',86:'scissors',87:'teddy bear',88:'hair drier',89:'toothbrush',
90:'hair brush'}다음으로는 object detection을 수행한다.
# 원본 이미지가 Faster RCNN기반 네트웍으로 입력 시 resize된다.
# scaling된 이미지 기반으로 bounding box 위치가 예측 되므로
#이를 다시 복구하기 위해 원본 이미지 shape정보 필요하다.
rows = img.shape[0]
cols = img.shape[1]
# 별도의 이미지 배열 생성한다.
draw_img = img.copy()
# 원본 이미지 배열 BGR을 RGB로 변환하여 배열 입력.
#여기서 swapRB=True는 BGR형태의 원본을 RGB형태로 바꾸는것을 의미한다.
cv_net.setInput(cv2.dnn.blobFromImage(img, swapRB=True, crop=False))
# Object Detection 수행하여 결과를 cvOut으로 반환
cv_out = cv_net.forward()
print(cv_out.shape)
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출한다
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.5 이상만 추출한다
if score > 0.5:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산한다.
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names_seq 딕셔너리로 class_id값을 클래스명으로 변경.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)중간의 cv_out의 일부 결과를 잠깐 살펴보면

왼쪽과 같은데 총 7개의 정보가 한 배열에 담겨져 있다. 1번째 정보는 의미없는 정보라고 한다.
2번째는 detection된 object의 label값, 3번째는 score정보, 4,5번째는 xmin, ymin, 6,7번째는 xmax, ymax의 좌표값을 의미한다.
다음과 같이 이미지 분석 결과
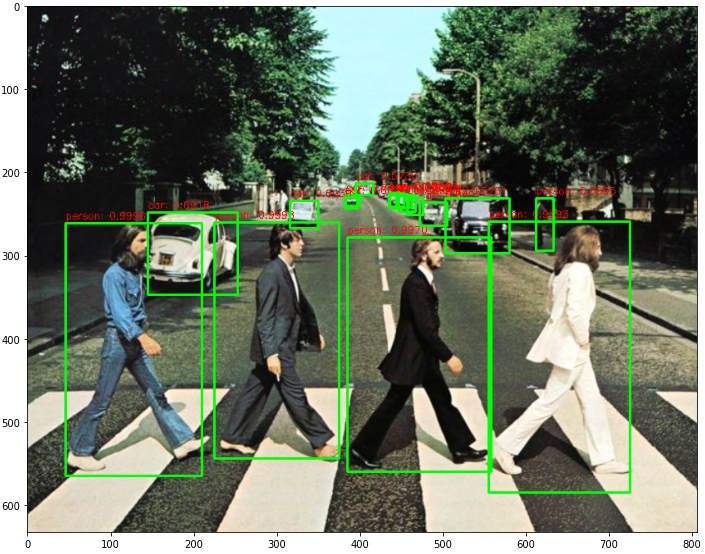
꽤 뛰어난 예측 결과를 보여준다. 하지만 수행시간이 대략 8초가 걸렸다. 따라서 실시간 detection에는 적합하지는 않은 모델인 것 같다.

다른 이미지에서도 뛰어난 detection성능을 보여줌을 알 수 있다.
다음으로는 비디오 기반으로 detection하는 실습이다. 비디오 기반이여도 실제로 동작은 비디오의 한 frame 별로 동작을 하기때문에 위의 이미지 기반 detection과는 많이 다르지 않다.
먼저 videocapture함수를 이용하여 video의 속성을 알아낸다,
video_input_path = '/content/data/Jonh_Wick_small.mp4'
cap = cv2.VideoCapture(video_input_path)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)다음으로는 video의 input 경로와 output 경로를 설정과 비디오의 코덱 설정을 한 후 videowrite함수를 사용하여 해당 비디오를 읽는다.
video_input_path = '/content/data/Jonh_Wick_small.mp4'
video_output_path = './data/John_Wick_small_cv01.mp4'
cap = cv2.VideoCapture(video_input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS )
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)다음은 frame 별로 iteration 하면서 detection을 수행한다. 큰 틀은 위에서 진행했던 정적이미지에서 object detection한 것과 유사하다.
# bounding box의 테두리와 caption 글자색 지정한다.
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:#비디오의 frame이 끝날때 까지 진행
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
rows = img_frame.shape[0]
cols = img_frame.shape[1]
# 원본 이미지 배열 BGR을 RGB로 변환하여 배열 입력
cv_net.setInput(cv2.dnn.blobFromImage(img_frame, swapRB=True, crop=False))
start= time.time()
# Object Detection 수행하여 결과를 cv_out으로 반환
cv_out = cv_net.forward()
frame_index = 0
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.5 이상만 추출
if score > 0.5:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names_0딕셔너리로 class_id값을 클래스명으로 변경.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(img_frame, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(img_frame, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, red_color, 1)
print('Detection 수행 시간:', round(time.time()-start, 2),'초')
vid_writer.write(img_frame)#detection이 완료된 frame을 frame별로 비디오에 넣는다.
vid_writer.release()
cap.release()총 58개의 frame을 detection하는데 10분 이상이 걸렸다.
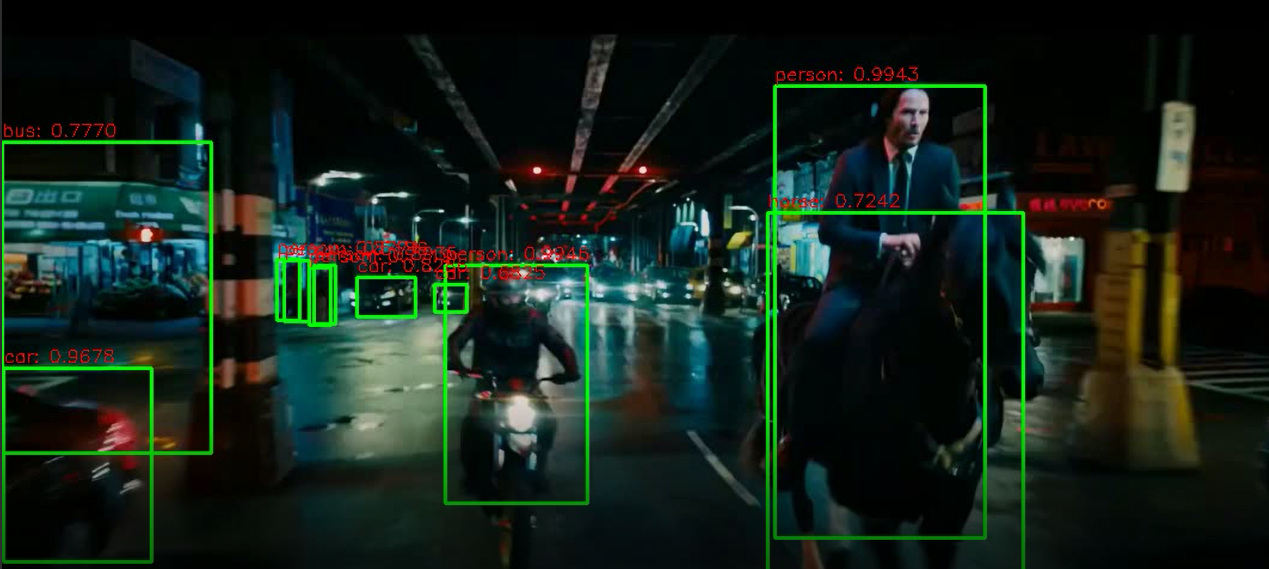
완료된 video를 살펴보면 중간중간 위의 frame과 같이 bus로 오인한 frame도 존재하는데 꽤 괜찮은 성능을 보인다.
'computervision > 섹션 3. RCNN 계열 Object Detecter(RCNN, SPPN' 카테고리의 다른 글
| Faster RCNN 개요 (0) | 2021.12.31 |
|---|---|
| Fast RCNN 개념 (0) | 2021.12.30 |
| SPP(Spatial Pyramid Pooling) Net 개요 (0) | 2021.12.30 |
| RCNN 개념 (0) | 2021.12.29 |